
[ECS] ECS Capacity Provider - Deep Dive
개요
ECS Capacity Provider 도입 검토를 진행중이며 공식문서/Blog 내용을 참조하여 Capacity Provider 특성에 대하여 이해한 내용을 바탕으로 정리한 내용이다. 공식 블로그 글을 읽고 내용 이해가 잘 되지 않는 부분은 AWS SA 분에게 도움을 받았다.
[+] https://aws.amazon.com/ko/blogs/containers/deep-dive-on-amazon-ecs-cluster-auto-scaling/
Deep Dive on Amazon ECS Cluster Auto Scaling | Amazon Web Services
Introduction Up until recently, ensuring that the number of EC2 instances in your ECS cluster would scale as needed to accommodate your tasks and services could be challenging. ECS clusters could not always scale out when needed, and scaling in could imp
aws.amazon.com
이용 목적
ECS Capacity Provider 도입을 검토하고자 하는 이유로서는 서비스 특성때문이다.
서비스 특성상 예고 없이 spike 성의 트래픽이 자주 발생하는 서비스 특징을 지닌다. 예기치 못한 상황에서 순간적으로 급증/급감하는 트래픽에 따른 유연성이 부족한 현황이다.
- Scale-Out 과정이 완료(Ready to Serve)되는 시점에서 급증한 트래픽이 다시 급감하여 비효율적인 리소스들을 사용하는 상황 발생한다.
- Scale-Out 메커니즘이 발현된 시점에서 언제 다시 급증하기에는 모르는 상황이기에 함부로 Scale-In을 할 수 없는 상황이다. (현재 수동으로 Scale-In 진행중) 그렇기에 적절한 상황에서의 Scale-In 을 통해 비용절감이 필요하다.
ECS Capacity Provider - Deep dive
Part 1. Capacity Provider Reservation
한마디로, ECS Capacity Provider는 컨테이너 레벨에서의 리소스 상황에 따라 자동으로 Scale In/Out 메커니즘을 발현하여 운영자가 최적의 인스턴스 수량에 대한 고려를 하지 않도록 관리의 편의성을 제공한다.
여기서 리소스 상황은 어떠할 때인지 그리고 어떻게 자동으로 Scale in/Out 메커니즘을 발현하여 관리의 편의성을 제공하는지 한층 한층 알아가보자.
- ECS CAS(Cluster Auto Scaling)는 AWS Auto Scaling에 의지한다.
- CAS는 ASG에 scaling plan을 생성하는데 여기서 target tracking scaling policy 방식이 적용된다.
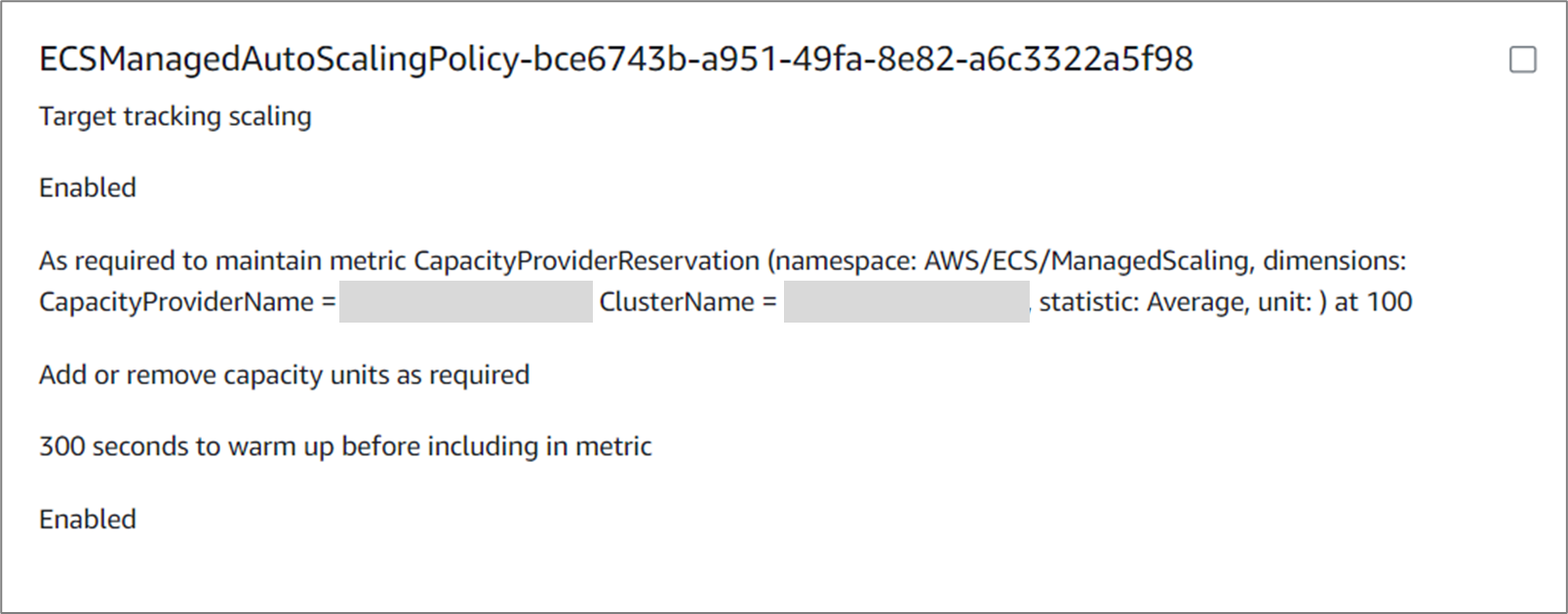
Capacity Provider 적용 시 ASG > Automatic Scaling 자동 생성 - scaling policy는 CapacityProviderReservation 의 CW 메트릭을 이용하는데, 이는 어플리케이션 수요에 맞게 알아서 ASG의 용량을 조절해주는 역할을 한다.
ECS Capacity Provider 를 올바르게 이용하기 위해서는 Capacity Provider Reservation 에 대한 속성값 이해가 중요하다. 이에 대하여 조금 더 알아가보자.
CapacityProviderReservation은 기본적으로 아래와 같이 정의된다. (이제부터, CapacityProviderReservation 줄여서 CPR이라고 명명을 하겠다.)
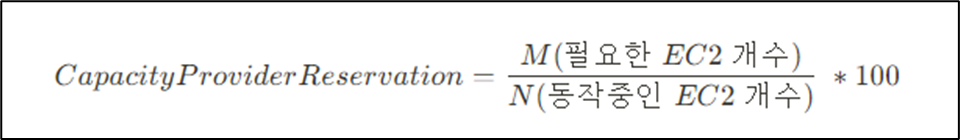
ECS CAS는 CPR 기준을 항상 만족할 수 있도록 EC2 개수를 조절한다. 여기서 CPR 설정값은 운영자가 직접적으로 설정해야 하는 속성값이다. 콘솔 화면에서는 "Set target capacity %" 정의되어 있다.

그렇다면 이 %가 의미하는 것은 무엇인지에 대하여 감이 잘 오지 않는 사람들이 많을 것이다. 상황에 대한 예를 들어 이해를 해보자.
Case 1. CPR = 100으로 설정하는 경우

- M = N인 경우: 운영에 필요한 EC2 개수와 동작중인 EC2 개수와 동일하므로 별도의 Scaling 메커니즘이 발현되지 않는다.
- M > N 인 경우: 필요한 EC2 개수보다 동작중인 EC2 개수가 적으므로 Scale-Out 메커니즘이 발현된다.
- M < N 인 경우: 필요한 EC2 개수보다 동작중인 EC2 개수가 많으므로 Scale-In 메커니즘이 실행될 수 있다.
Case 2. CPR = 50으로 설정되는 경우
- 예를 들어 서비스 운영에 필요한 인스턴스가 2대인 경우, 2대의 예비 인스턴스를 추가로 구비한다.
- 예비 인스턴스에서는 Task가 별도로 할당되지 않은 상태이다

- 구성된 예비 인스턴스들은 EC2 Auto Scaling에서 제공하는 Warm pool 기능을 활용하여 구성되었다. 그렇기에 인스턴스 비용은 청구가 되어지며 ECS Task 비용은 별도로 청구되지 않는다.
Amazon ECS supports Amazon EC2 Auto Scaling warm pools. A warm pool is a group of pre-initialized Amazon EC2 instances ready to be placed into service. Whenever your application needs to scale out, Amazon EC2 Auto Scaling uses the pre-initialized instances from the warm pool rather than launching cold instances, allows for any final initialization process to run, and then places the instance into service.
내용의 이해를 돕기위해 추가 그림으로 설명하면, 다음과 같다.
① 운영에 요구되어지는 인스턴스 수량은 10(=M)개로 CAS가 판단하며 CPR = 0.5를 만족하기 위해 EC2를 20대 생성을 진행한다. 여기서 10대는 예비 인스턴스로 구성되어지며 별도의 Task는 할당되지 않는다.
② ~ ③ Spike성 트래픽이 발생하는 경우, CAS가 운영에 요구되어지는 수량은 20(=M)으로 판단하는 경우(가정), CPR = 0.5를 만족하기 위해 동작중인 EC2는 총 40대가 되어지게 된다. 여기서 20대는 예비 인스턴스로 이루어진다.
④ ~ ⑤ Spike 성 트래픽이 다시 발생하는경우, CAS 가 운영에 요구되어지는 수량은 40(=M)으로 판단하는 경우(가정) CPR = 0.5를 만족하기 위해 동작중인 총 EC2는 80대로 구성되며, 여기서 40대는 예비 인스턴스로 이루어진다.
(* 예비인스턴스 = Task가 할당되지 않은 인스턴스)


Part 2. M에 대한 고찰
Capacity Provider Reservation 에 대해서 한가지 의문이 들 것이다. M(필요한 인스턴스 개수)는 어떤 근거로 산정이 되어지는 부분이다.
공식 문서/블로그 내용을 보았을 때, CAS에서 정의하는 M 은,
"필요한 인스턴스(M) 적절한 개수를 선정하는 것은 굉장히 어려운 부분이며 이러한 고민을 덜어줄 수 있도록 CAS는 적절한 M값을 구하는데 있어 좋은 추론을 해주는 역할을 수행한다. 여기서 M은 서비스를 운영하는데 최소로 필요한 개수이다"
[+] https://aws.amazon.com/ko/blogs/containers/deep-dive-on-amazon-ecs-cluster-auto-scaling/
Since we can’t in general know the optimal value of M, CAS instead tries to make a good estimate. CAS can estimate a lower bound on the optimal number of instances to add based on the instance types that the ASG is configured to use, and use that value for M. In other words, you will need at least M more instances to run all of the provisioning tasks. CAS calculates M in this case as follows:
여기서 중요한 특징중 하나는, 구성되는 예비 인스턴스들(증설대상)에 대하여 Spot Instance + 다른 EC2 Type을 지정할 수 있으며 이를 통해 비용절감의 효과를 기대할 수 있다.
‘M’ 값의 산정은 기본적으로 binpack 방식으로 계산이 이루어지며 실제 scaling을 binpack으로 진행한다.
(하지만 사용자가 지정한 placement strategy가 있다면 이 기준이 우선적으로 적용 된다.)
예를 들자면, 1개의 Task가 2 CPU, 메모리 8G, 를 사용하도록 정의 되어 있고 Task가 할당된 인스턴스 유형은 g5.4xlarge (vCPU 16, GPU memory 24GB) 로 주어지는 상황을 가정하자.
여기서, 트래픽 유입으로 10개의 추가 task가 필요해 진다고 하면 총 20 CPU, 80G 메모리가 필요되어진다. 필요한 총 CPU 개수는 20개 이므로 이를 충족하기 위해 필요한 ‘M’은 2개가 되지만 (20/16 = 1.25) GPU 메모리 필요량은 80GB 이므로 필요한 ‘M’은 4개이다. (80/24 = 3.33..)
이 경우 필요한 M은 4로 산정이 된다.
Scaling이 되어 결정되는 최종 M의 값은 [N + minimumScalingStepSize, N + maximumScalingStepSize] 의 범위를 벗어나지 않는다.
- minimumScalingStepSize , maximumScalingStepSize 값은 항상 양의 값으로 정해져야 하며. minimumScalingStepSize = 1 , maximumScalingStepSize = 10000 의 기본값을 지니게 된다.
- minimumScalingStepSize, maximumScalingStepSize 값 설정은 CLI 명령어를 통해서만 조정이 가능하다.
[+] https://docs.aws.amazon.com/cli/latest/reference/ecs/create-capacity-provider.html
create-capacity-provider — AWS CLI 1.30.6 Command Reference
Note: You are viewing the documentation for an older major version of the AWS CLI (version 1). AWS CLI version 2, the latest major version of AWS CLI, is now stable and recommended for general use. To view this page for the AWS CLI version 2, click here. F
docs.aws.amazon.com
추가 검토사항
블로그 내 ECS Capacity Provider 을 이용하는데 있어 ECS Task 배치 제약 유형으로 distinctInstace 외엔 권장하지 않는다고 해석되는 문구.
Task placement constraints are considered. However, any placement constraint other than distinctInstance is not recommended.

distinctInstance 내용을 이해하기 위해 아래 공식문서 내용을 참조해본 결과, distinctInstance EC2 : Task 비율을 1:1 로 가져가는 것으로 해석이 되는데 여기서, CAS를 이용하는 경우 1인스턴스에 1 task가 할당되도록 권장하는 내용인지 확인 필요.
[+] https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task-placement-constraints.html

참고
https://aws.amazon.com/ko/blogs/containers/deep-dive-on-amazon-ecs-cluster-auto-scaling/
Deep Dive on Amazon ECS Cluster Auto Scaling | Amazon Web Services
Introduction Up until recently, ensuring that the number of EC2 instances in your ECS cluster would scale as needed to accommodate your tasks and services could be challenging. ECS clusters could not always scale out when needed, and scaling in could imp
aws.amazon.com
Optimize cost for container workloads with ECS capacity providers and EC2 Spot Instances | Amazon Web Services
Amazon EC2 Spot Instances use spare Amazon Elastic Compute Cloud (Amazon EC2) capacity at up to a 90% discount compared to On-Demand prices. Amazon EC2 can interrupt Spot Instances with a two-minute notification when EC2 needs the capacity back. Spot I
aws.amazon.com
'AWS > AWS 알아두면 좋은 지식' 카테고리의 다른 글
| [ElastiCache] 암호화 설정여부에 따른 Redis 엔드포인트 구조 변경점 (0) | 2024.04.27 |
|---|---|
| [Keyspace] Hot Partition - Deep Dive (3) | 2024.01.19 |
| [AWS] CloudWatch agent를 통한 Group 레벨 메모리 메트릭 관찰하기 (0) | 2023.11.10 |
| [AWS] ACM 인증서 - Deep Dive (인증서 구조, Amazon Root CA, ACM 다운로드) (0) | 2022.12.01 |
| [EKS] ALB Ingress Controller 필요성 (0) | 2022.09.05 |
댓글